


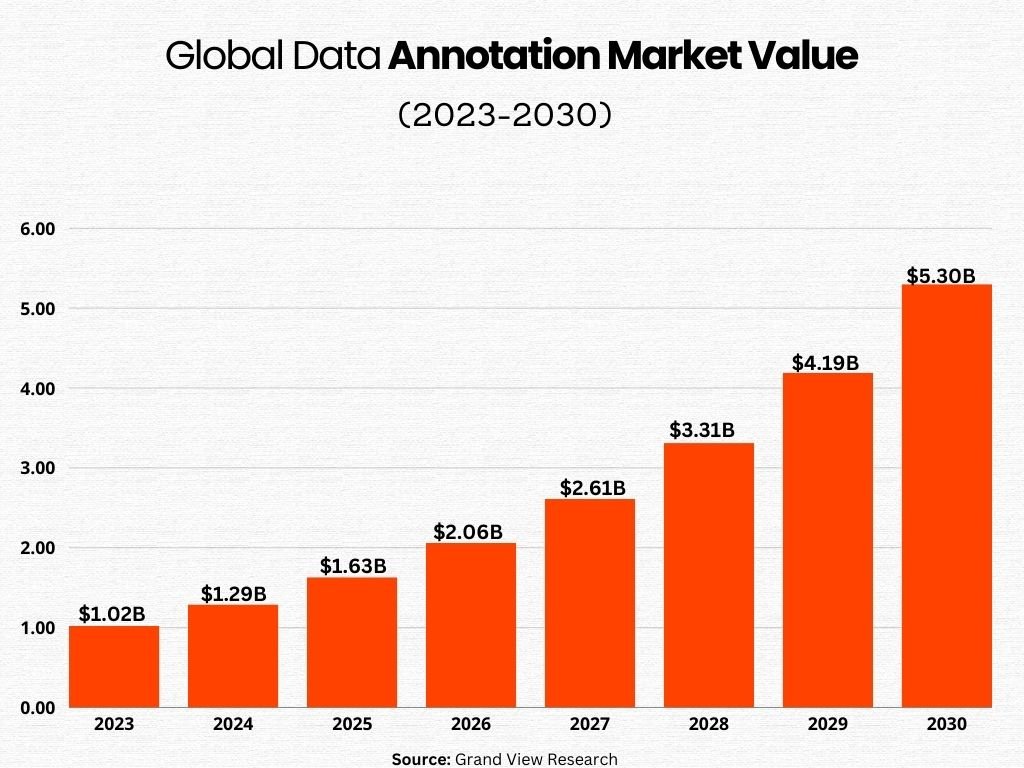
2500+
Successful Projects


When we talk about global technology trends nowadays - artificial intelligence and machine learning are no left just buzzwords but something that are here to redefine the future. But have you ever thought about what’s making these technologies effective and efficient? It’s data. Whether it’s a machine learning or AI model, everything starts with data. Additionally, the quality of training data is the most significant determinant of the model’s efficiency. For instance, have you ever wondered how Face ID unlock features on your iPhone work so perfectly? To develop such an advanced AI-enabled system, the demand for “data annotation” and “data labeling” has increased significantly.
But what exactly is data annotation, and how does it work? Well, it is a complex process often carried out by expert data annotators who work with raw data sets and train them for machine learning algorithms. The process makes data more understandable and processable for ML models.
If we talk about 5-10 years back, data annotation wasn’t as crucial as it is today. However, it is not as prevalent as data labeling. Therefore, companies dealing with AI often struggle with data annotation and don’t know where to start. If you’re one of them, here’s a guide explaining the basics of data annotation, the types of data annotations available, and why it has become a necessity for businesses these days.
Table of Contents
Data annotation is the process of marking up data with labels that help machine learning models identify and categorize the data they use. It is very similar to teaching a child to recognize and name objects. Data annotation is crucial for training AI systems, allowing them to process and understand diverse data sets, from images and audio clips to video sequences and text documents.
An ML model interprets visual content by employing computer vision, an AI subset that equips software and machines with the ability to digest and interpret digital visuals. It involves meticulously tagging data with labels to train computer vision systems to recognize elements within images or videos.
The data annotation process is classified into two primary phases:
Now that you have understood the basics of data annotation, let’s move forward to discuss the different types available:
Data annotation is the meticulous process of labeling data across various formats—images, texts, audio, and video—to train AI systems. The process is classified into four main types including.
This is crucial for technologies like facial recognition and computer vision. Specialists in AI train models by tagging images with descriptive captions and keywords, which the algorithms use to learn and make sense of visual data.
Audio Annotation does the complex task of dissecting audio files to tag various elements such as language, accent, sentiment, and even the speaker's demographic details. It's a process that goes beyond words, capturing the nuances of mood, intent, and even the ambient sounds that provide context. Techniques like timestamping and audio labeling give algorithms a full spectrum of auditory information for accurate processing.

Video Annotation takes the concept further, dealing with the dynamic nature of videos—essentially sequences of still images, or frames, that together depict motion. Each frame is meticulously marked with key points, polygons, or bounding boxes to identify and track objects across the video.
This granular approach allows AI models to understand movement and behavior, laying the groundwork for advanced features like object localization and motion tracking in real-time applications.
Text annotation trains machine learning models with a deeper understanding of human language. It's a process of converting raw data into insightful training data sets. Text data can range from a user's review on an app to a tweet, each carrying complex layers of meaning.
Humans naturally understand the subtleties of language—sarcasm, humor, and underlying messages. However, machines lack this human behavior. That’s where text annotation can help by labeling text to help AI understand the abstract complexity of our words.
Through these stages, text annotation trains AI with the ability to interpret text as more than just data but to understand human expression and intent.
The importance of data annotation in this era of artificial intelligence can’t be overstated. It acts as a trainer for machine learning algorithms for continuous learning and improvement.
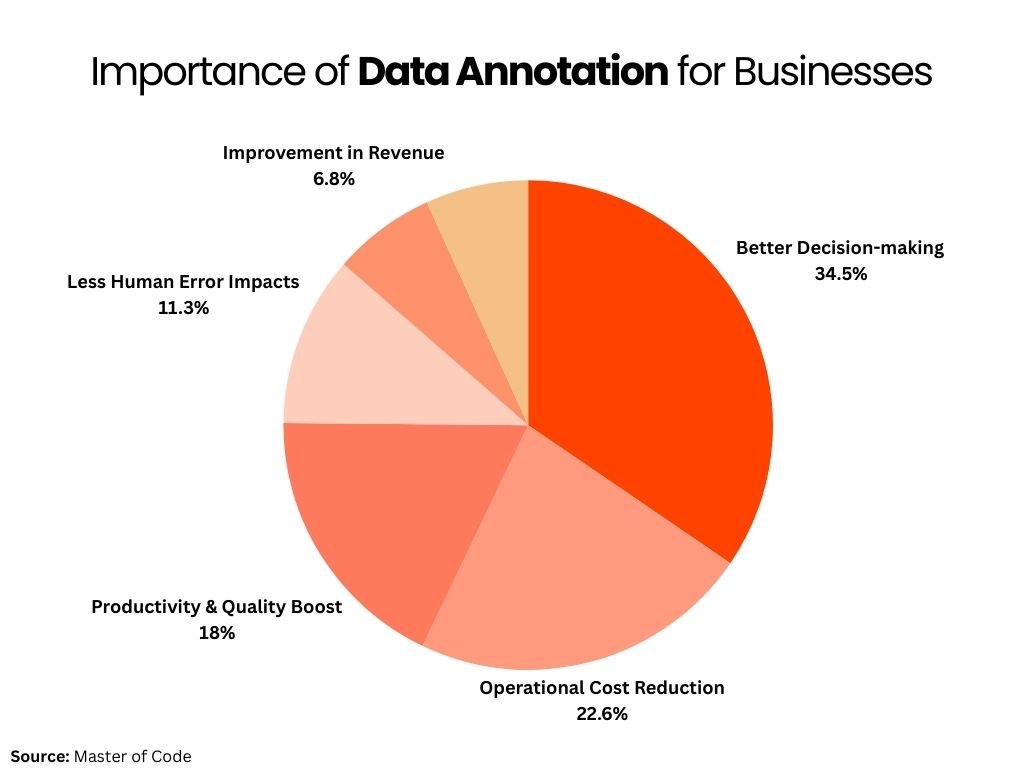
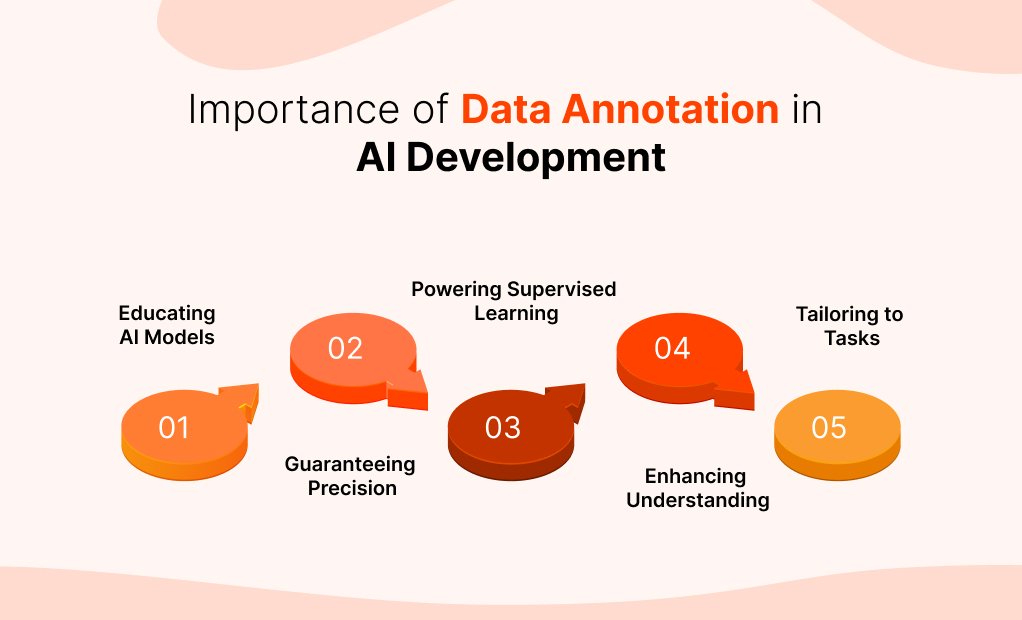
Here are some reasons signifying the importance of data annotation in AI development:
Think of data annotation as the textbook for AI. It offers labeled examples that serve as lessons, teaching models to identify patterns and make smart decisions, whether it's recognizing a face or parsing a sentence.
The popular saying, 'garbage in, garbage out,' holds true here. Precise annotations are the backbone of trustworthy AI, ensuring that the data it learns from is of the highest caliber, sharpening its performance.
Much like a teacher's guidance, annotated data is vital for supervised learning. It provides the 'answers' that help models learn and adapt to new, unseen data.
Annotated data does more than train; it also helps us interpret AI decisions. Knowing what data the model learned from allows us to peek into its 'thought' process.
Just as different jobs require different tools, various AI tasks need customized annotations. From spotting objects to diagnosing diseases, annotations give AI the right context to excel in specific roles.
Large Language Models (LLMs) are like blank papers; they don't inherently understand the nuances of human language. They require training to understand language and respond aptly to user queries, even the most unusual ones. The precision of a Generative AI's response is rooted in its training, which enables it to understand context, intent, and subtleties like sarcasm.
Data annotation trains LLMs with this discerning ability. Here are some popular data annotation methods for LLMs:
This traditional approach involves individuals manually reviewing and labeling data. It's likehandcrafting a piece of art—meticulous, precise but also labor-intensive, and slow. The advantage is the high-quality, accurate data that comes from the human touch.

It's a hybrid method where the human eye catches nuances that machines might miss, and LLMs handle the heavy lifting of data processing. It's a balance between AI’s accuracy and human efficiency.
This method is all about speed and volume. LLMs autonomously tag and categorize large datasets, making them ideal for projects with tight deadlines or massive amounts of data. However, it may not be as precise as methods involving human oversight.
Think of this as customizing an LLM to fit specific needs. By training on specially selected labeled datasets, the LLM is fine-tuned to deliver more accurate and relevant responses, much like tailoring a suit for the perfect fit.
LLMs use their existing knowledge base to label new data without additional training. It's cost-effective and quick, suitable for when you have a lot of data and need to make sense of it fast.
This technique involves giving LLMs specific instructions to guide their data annotation. The quality of the output hinges on the clarity and precision of these prompts, similar to how a well-asked question leads to a better answer.
This is about outsourcing the data annotation to third-party providers who can supply large volumes of high-quality, ethically sourced labeled data. It ensures diversity and reduces bias, providing a solid foundation for LLM training.
Data Annotation has varied applications in different domains due to its efficiency and reliability.

Here are some of the industry-specific use cases of data annotation:
Data annotation is a critical tool for precision medicine in the healthcare industry. Annotating medical images, like MRI and CT scans, enables AI models to diagnose diseases more accurately. Similarly, labeling electronic health records (EHRs) and clinical notes can help identify trends and patterns in patient data, leading to better treatment plans and outcomes.
Data annotation can enhance customer experience by analyzing shopping patterns and preferences for the retail sector. Labeling product images allows AI to recommend similar items to customers, while annotating sentiment data from reviews and surveys helps businesses understand consumer feelings towards products or services, enabling personalized marketing strategies.
Financial data annotation is critical for risk management and compliance. By labeling transactional data, AI can detect abnormal patterns indicative of fraud. Annotating financial documents also aids in automating the extraction of relevant information, which is crucial for maintaining regulatory compliance and making informed investment decisions.
In the automotive industry, especially for autonomous vehicles, data annotation is used to train AI in object detection and decision-making. Labeling images and sensor data from vehicles helps AI perceive and navigate the driving environment accurately, recognizing everything from traffic signs to pedestrians, thus ensuring safer autonomous driving.
Industrial data annotation focuses on optimizing production and maintaining safety standards. Annotating images from manufacturing processes can help AI detect defects or irregularities, improving quality control. Labeling safety data ensures that AI systems can monitor compliance with safety regulations and predict maintenance needs, preventing accidents and downtime.
Data annotation is more than a cost-cutting tool; it's a foolproof process for enhancing AI capabilities. Here's a simplified breakdown of its advantages:
While these benefits are significant, it's also crucial to consider the limitations to get a complete understanding of data annotation's impact.
Data annotation is a critical yet challenging step in the AI and ML development cycle. Understanding these limitations is crucial for organizations to effectively manage the risks and challenges associated with data annotation in AI and ML projects.
Adhering to data annotation best practices is crucial to maximize the effectiveness of AI and ML models. These practices promote the precision and uniformity of your data:
Data annotation is essential for AI to understand and interact with the world. It's like teaching a child to read by pointing out words and explaining their meanings. By labeling data—images, text, audio, and video—AI learns to recognize patterns and make decisions.
This process is crucial across industries, from healthcare diagnosing diseases to self-driving cars navigating streets. However, it's not simple; it requires lots of data, advanced tools, and careful handling, especially with sensitive information. All in all, data annotation presents a training ground for AI, setting the stage for more ingenious technology that can improve our lives.
Annotating data for LLM involves labeling the data with relevant tags that the model can understand. This includes categorizing text, marking entities, or assigning sentiment. It's about providing context so the LLM can learn from examples.
To annotate a dataset, you must review the data and apply labels that accurately describe each element. Depending on your dataset, this could mean identifying objects in images, sentiments in text, or actions in videos.
Data annotation can be challenging as it requires attention to detail and an understanding of the context. The difficulty also depends on the complexity of the data and the specificity of the annotations required.
Many tools are available for data annotation, ranging from simple manual labeling software to more advanced platforms incorporating AI assistance. The choice of tool often depends on the data type and the scale of the annotation project.
Training for data annotation typically involves learning the principles of labeling, understanding the project's specific requirements, and becoming familiar with the tools and software that will be used for the annotation process.


Android Development
With people moving towards a mobile-centric world, mobile apps have evolved into a basic necessity for human life. For instance, if you need food but don’t want to cook, just use the food delivery app; if you’re getting late to the office, just book a cab from Uber, or if you need groceries, just order […]
Android Development
Suppose you are eagerly waiting for a movie, but find out that all the tickets are sold out. What would you do then? In such a situation, resorting to free movie download websites remains the only option left. There are thousands of free sites, but only a few have gained an immersed popularity, and one […]
Android Development
One active listener always concentrates intently on the speaker, and one note-taker records all significant ideas for future use. Not to add, both are necessary for a successful session. Artificial intelligence (AI) transcription technologies, such as Fireflies.ai, are revolutionizing video meetings and phone calls by converting spoken words into text and producing a summary. To […]
Successful Projects
Years in Business
Happy Customers
We have been working with Mtoag Technologies for the past 5 years. They have been a very responsible team from the beginning. They are quick at responding, available whenever we need, and are extremely supportive when there’s a high-priority fix. All-inclusive, IAD can be your best bet for app development.
